자연어처리 분야를 공부하다 보면 Pre-trained Language Model 중에 하나인 2018년에 제안된 BERT (Bidirectional Encoder Representations from Transformers) 모델을 들어보고 직접 사용해봤을 거 같습니다. 본 포스팅에서는 BERT 모델에서 사용한 Subword tokenizer 중에 하나인 WordPiece tokenizer에 대해서 공부하면서 스스로 던졌던 질문들을 정리하려고 합니다.
WordPiece Model (WPM)
WordPiece Model은 Byte Pair Encoder (BPE)의 변형 알고리즘입니다. 이하 WPM으로 명칭하겠습니다. BPE 알고리즘은 빈도수를 기반하여 가장 많이 등장한 token의 쌍을 병합하지만, WPM은 우도(Likelihood)를 가장 높이는 쌍을 병합니다.
처음 제안된 논문을 인용하여 WPM에 대해서 자세하게 소개하겠습니다. 또한, 구글에서 WPM을 변형하여 변역기에 사용했던 논문은 참고하시면 됩니다.
논문에서 설명하고 있는 WPM의 훈련 과정은 총 4가지로 되어 있습니다.
1) Initialize the word unit inventory with the basic Unicode characters (Kanji, Hiragana, Katakana for Japanese, Hangul for Korean) and including all ASCII, ending up with about 22000 total for Japanese and 11000 for Korean.
단어 유닛 목록을 ASCII, 22,000개 일본어, 11,000개 한국어를 Unicode 형태로 초기화 진행
Q1) Unicode 형태로 단어 유닛 목록을 생성하는 이유는?
2) Build a language model on the training data using the inventory from 1.
1) 과정을 통해 만들어진 단어 유닛 목록을 사용해서 training data에 대해서 language model 구축
Q2) 여기서 사용한 language model은 무엇인가?
3) Generate a new word unit by combining two units out of the current word inventory to increment the word unit inventory by one. Choose the new word unit out of all possible ones that increase the likeilihood on the training data the most when added to the model.
model(language model)에 결합한 2개의 단어 유닛을 추가했을 때 training data에 대해서 likelihood가 가장 증가하는 것을 새로운 단어 유닛으로 생성
Q3) likelihood가 증가하는 것을 채택하는 것은 알겠지만 어떻게 likelihood를 구하는가?
4) Goto 2 until a predefined limit of word units is reached or the likelihood increase falls below a certain threshold
미리 결정한 단어 유닛 목록의 크기에 도달하거나 likelihood의 증가량이 특정 임계점보다 떨어질 때까지 2~3번 과정 반복
논문의 WPM 훈련 과정을 인용하면서 요약 및 저 스스로 질문했던 것들을 적어보았습니다. 그럼 제가 논문을 보고 정리하고 약간의 유추한 내용도 추가해서 답변을 하겠습니다.
Q1) Unicode 형태로 단어 유닛 목록을 생성하는 이유는?
A) WPM 모델은 일본어, 한국어뿐만 아니라 새로운 언어에 대해서도 사용이 가능하게 만들기를 원했습니다. 그래서 전세계의 모든 문자를 표현할 수 있는 Unicode 형태로 단어 유닛 목록을 생성하였습니다.
Q2) 여기서 사용한 language model은 무엇인가?
A) 논문의 4장 Language Modelining 부분에 자세히 나와 있습니다. 해당 부분을 보면 N-gram 알고리즘 중에서 3~5-grams을 Katz back-off language model과 함께 사용한 것이다.

그렇다면 katz back-off language model은 무엇인가?
Katz-back-off language model은 n-gram에서 주어진 히스토리가 주어진 단어의 조건부 확률을 추정하는 생성 n-gram 언어 모델입니다. 그리고 최대 가능성 추정(maximum likelihood estimation)을 사용하여 서로 다른 n-gram 차수에 대해 개별 모델을 훈련한 다음 함께 보간하여 구성하는 모델입니다.
즉, 1개의 n-gram이 아닌 서로 다른 n-gram을 사용하여 word unit을 결합하였을 때 likelihood가 최대가 되는 word unit 조합을 찾는 것입니다.
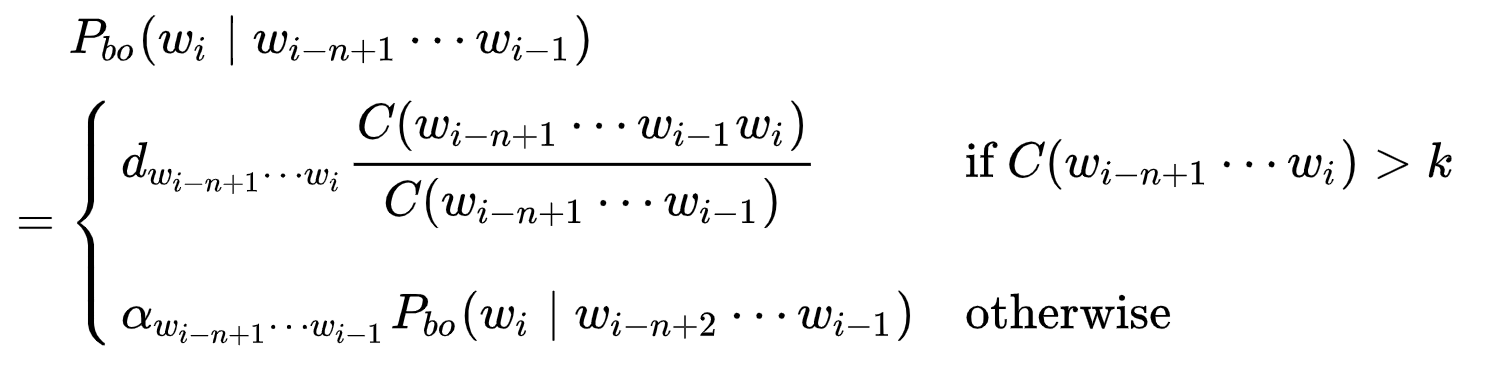
Q3) likelihood가 증가하는 것을 채택하는 것은 알겠지만 어떻게 likelihood를 구하는가?
A) 위에서 말씀드린 것과 같이 3~5 grams를 통해서 Pre-tokenize 과정을 거친 후에 katz back-off language model을 통해서 단어의 조합에 대한 확률을 계산하여 likelihood가 최대가 되는 단어의 조합을 찾아 결합하는 것이다.